
Data Science: A Quick Overview
At a basic level, the data science process looks something like this:
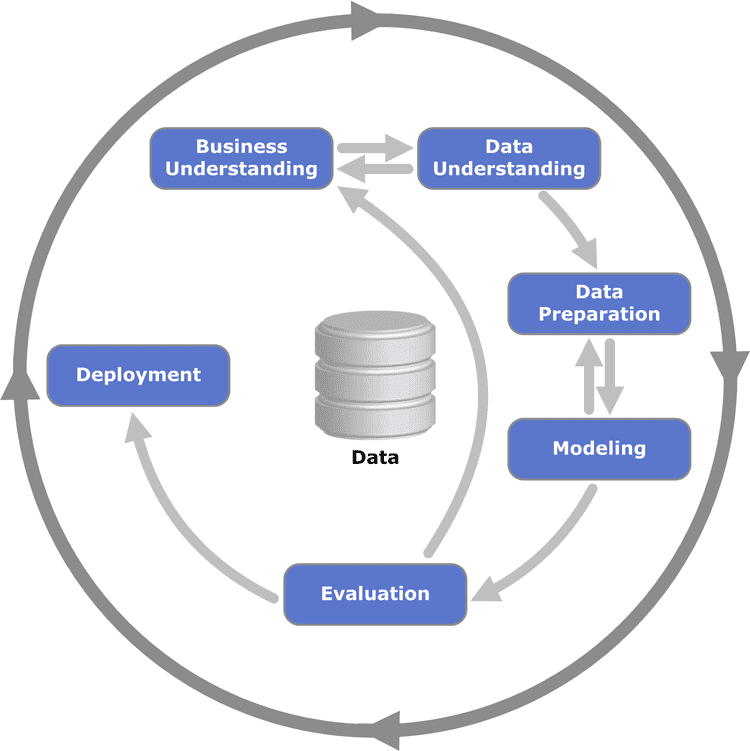
- Start with hypothesis or problem to solve
- Source raw data to help solve problem/investigate hypothesis
- Clean data into a usable format
- Explore data to understand what you are working with
- Analyze and model data to try to find relationships between variables
- Make conclusions about your findings (or lack thereof)
Python has become a popular language for data science as a result of its simple syntax, object-oriented
nature, and amazing open-source community. However, Python on its own does not lend itself well to data
science. That is where the power of open-source projects such as pandas, numpy, sklearn, and countless
other projects come into play.
Predicting Boston House Prices: The Hard Way
A basic data science workflow might look something like this:
1import pandas as pd2from sklearn.datasets import load_boston3from sklearn.model_selection import train_test_split4from sklearn.linear_model import LinearRegression56# Load data7boston = load_boston()8X = pd.DataFrame(boston.data, columns=boston.feature_names)9y = pd.DataFrame(boston.target, columns=['Price'])1011# Break into training and testing data12X_train, X_test, y_train, y_test = train_test_split(X, y)1314# Model data15reg = LinearRegression()16reg.fit(X_train, y_train)1718# Test model19reg.score(X_test, y_test)
The code above is great for short data science pipelines. However, you probably want to do more than just try a linear regression model. There are lots of different model types that could be fitted to this data. How can we change the code above to run a SVM regression or a decision tree regression?
Well, that isn't too bad. We just add the following few lines:
1from sklearn.tree import DecisionTreeRegressor2from sklearn.svm import SVR34# Model data5reg_dt = DecisionTreeRegressor()6reg_svr = SVR()78reg_dt.fit(X_train, y_train)9reg_svr.fit(X_train, y_train)1011# Test models12reg_dt.score(X_test, y_test)13reg_svr.score(X_test, y_test)
The code above is quickly starting to look repetitive. Let's make functions to reduce our code duplication.
1def train_and_score(model, X_train, y_train, X_test, y_test):2 model.fit(X_train, y_train)3 return model.score(X_test, y_test)45train_and_score(LinearRegression(), X_train, y_train, X_test, y_test)6train_and_score(DecisionTreeRegressor(), X_train, y_train, X_test, y_test)7train_and_score(SVR(), X_train, y_train, X_test, y_test)
Now what if we want to change which combination of features we are testing. For example, let's say we want to limit our features to property tax per \$10k (TAX), per capita crime rate (CRIM), and average number of rooms per dwelling (RM).
Now we have to go back to when we loaded our data and do the following:
1X = pd.DataFrame(boston.data, columns=boston.feature_names)2X = X[['TAX', 'CRIM', 'RM']]
This isn't bad if we are just trying out a few combinations of features; however, what if it took a long time
to get to load our X variable, because we were pulling it from an external API? Even for only a few combinations
of features, you would need to load X every time you used a new combination of features or save it somewhere using
code like this:
1def load_features():2 if os.path.exists('/path/to/features.csv'):3 with open('path/to/features.csv') as f:4 X = pd.read_csv(f)5 else:6 boston = load_boston()7 X = pd.DataFrame(boston.data, columns=boston.feature_names)
This is becoming messy quickly. It would be nice if we didn't have to manually specify where to save data we had already collected or manipulated.
In order to avoid repetitive code and running the same tasks over and over again, we can use d6tflow.
Predicting Boston House Prices: The Easy Way
We can break down the pipeline we created the hard way above into 3 separate tasks.
- Load data
- Model data
- Test model(s)
The d6tflow library provides us with a convenient OOP way of doing this and saving our outputs along the way
so that we don't run the same calculations again if we don't need to.
First, we will import the modules we will need:
1import d6tflow2import luigi3import pandas as pd4from sklearn.datasets import load_boston5from sklearn.model_selection import train_test_split6from sklearn.linear_model import LinearRegression7from sklearn.tree import DecisionTreeRegressor8from sklearn.svm import SVR
In our first task, we load our data. We use persist to tell d6tflow what variable names
will need to persist across tasks since we are saving more than one pandas data frame (which will create
multiple parquet files).
1# Save pandas outputs to parquet files2class LoadData(d6tflow.tasks.TaskPqPandas):3 # So that you get the same results4 seed = luigi.IntParameter(default=0)56 persist = ['X_train', 'X_test', 'y_train', 'y_test']7 def run(self):8 boston = load_boston()9 X = pd.DataFrame(boston.data, columns=boston.feature_names)10 y = pd.DataFrame(boston.target, columns=['Price'])11 X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=self.seed)12 self.save({'X_train': X_train, 'X_test': X_test,13 'y_train': y_train, 'y_test': y_test})
In our second task, we require that our first task has run and then load that data to fit our model.
To provide flexibility to which model we will use, we will add a luigi parameter. The luigi library
was made by Spotify to build complex data pipelines. By using d6tflow, we remove a lot of the boilerplate
code from luigi.
1@d6tflow.requires(LoadData)2class ModelData(d6tflow.tasks.TaskPickle):3 model = luigi.Parameter(default=LinearRegression())45 def run(self):6 X_train = self.input()['X_train'].load()7 y_train = self.input()['y_train'].load()8 model = self.model9 model.fit(X_train, y_train)10 self.save(model)
Finally, we fit our data to our model.
1@d6tflow.requires(LoadData, ModelData)2class TestModel(d6tflow.tasks.TaskPickle):34 def run(self):5 X_test = self.input()[0]['X_test'].load()6 y_test = self.input()[0]['y_test'].load()7 model = self.input()[1].load()8 score = model.score(X_test, y_test)9 self.save(score)
Now, to run our model we simply need to call the run() method from d6tflow. To load the result, we can
use the outputLoad() method.
1task = TestModel() # Uses linear regression as default2d6tflow.run(task)3score = task.outputLoad()4print("Score is", round(score, 4))
Score is 0.6355
Now it is extremely simple to switch which model we use. And, as an added bonus, we don't even have to run the data loading task again. We can simply load the results from memory. Here is how simple it is to change which model we use for our regression:
1# Choose a sklearn regressor2task = TestModel(model=DecisionTreeRegressor())
After running the decision tree regressor model and printing the score output, we get
Score is 0.6523
That was a really easy way to swap out models! Of course, with any programming project, the benefits from the minimal d6tflow boilerplate code are typically
not recognized until you are a few hundred lines into your machine learning project/data science pipeline.
However, if you are pulling lots of data from an external data source writing the LoadData task alone will save you time, as your data will be saved and ready for use by all downstream tasks.
Conclusion
Many beginner data science articles string together commands in one file, because it is simple. However, in real-world scenarios, you will quickly find that this approach does not scale.
The d6tflow library helps solve this problem while adding only a minimal amount of boilerplate code. Further, the time spent on writing the boilerplate code makes your pipeline
extremely flexible and will speed up your fine-tuning of your model tremendously.
